k8s中管理CPU资源管理的动态
k8s的cpuManager完成节点侧的cpu资源分配和隔离(core pinning and isolation,如何做到隔离)。
- 发现机器上的cpu拓扑
- 上报给k8s层机器的可用资源(包含kubelet侧的调度)
- 分配资源供workload执行
- 追踪pod的资源分配情况
本文大致介绍k8s中CPU管理的现状与限制,结合社区文档分析当前社区动态。
- CPU管理的现状与限制
- 相关的issues
- 社区提案
CPU管理的现状与限制
kubelet将系统的cpu分为2个资源池:
- 独占池(exclusive pool):同时只有一个任务能够分配到cpu
- 共享池(shared pool):多个进程分配到cpu
原生的k8s cpuManager目前只提供静态的cpu分配策略。当k8s创建一个pod后,pod会被分类为一个QoS:
- Guaranteed
- Burstable
- BestEffort
并且kubelet允许管理员通过 –reserved-cpus指定保留的CPU提供给系统进程或者kube守护进程(kubelet, npd)。保留的这部分资源主要提供给系统进程使用。可以作为共享池分配给非Guaranteed的pod容器。但是Guaranteed类pod无法分配这些cpus。
目前k8s的节点侧依据cpuManager的分配策略来分配numa node的cpuset,能够做到:
- 容器被分配到一个numa node上。
- 容器被分配到一组共享的numa node上。
cpuManager当前的限制:
- 最大numa node数不能大于8,防止状态爆炸(state explosion)。
- 策略只支持静态分配cpuset,未来会支持在容器生命周期内动态调整cpuset。
- 调度器不感知节点上的拓扑信息。下文会介绍相应的提案。
- 对于线程布局(thread placement)的应用,防止物理核的共享和邻居干扰。cpu manager当前不支持。下文有介绍相应的提案。
相关issues
- 针对处理器的异构特征,用户可以指定服务所需要的硬件类别。
https://github.com/kubernetes/kubernetes/issues/106157
异构计算的异构资源有着不同额性能和特征和多级。比如Intel 11th gen,性能内核(Performance-cores, P-cores)是高性能内核,效率内核(Efficiency-cores,)是性能功耗比更优的内核。
ref: https://www.intel.cn/content/www/cn/zh/gaming/resources/how-hybrid-design-works.html
这个issue描述的用户场景是,可以将E-cores分配给守护进程或者后台任务,将P-cores分配给性能要求更高的应用服务。支持这种场景需要对CPU进行分组分配。但是issue具体的方案讨论。因为底层硬件差异,目前无法做到通用。目前k8s层需要设计重构方案。
当前相关需求的落地方案都是在k8s上使用扩展资源的方式来标识不同的异构资源。这种方法会产生对于原生cpu/内存资源的重复统计。
- topologyManager的best-effort策略优化
https://github.com/kubernetes/kubernetes/issues/106270
issue 提到best-effort的策略,迭代每个provider hint,依据位与运算聚合结果。如果最后的结果为not preferred,topologyManager应该尽力依据资源的倾向做到preferred的选择。这个想法的初衷是因为cpu资源相比其他外设的numa 亲和更重要。当多个provider hint相互冲突时,如果cpu有preferred的单numa node分配结果,应该先满足cpu的分配结果。比如cpu返回的结果为 [‘10’ preferred, ‘11’ non-preferred]),一个设备返回的结果[‘01’, preferred]。topologyManager应该使用'10’ preferred作为最后的结果,而不是合并之后的'01’ not preferred。
而社区对于这种的调度逻辑的改变,建议是创建新的policy以提供类似调度器优选(scoring)的算法系统。
- 严格的kubelet预留资源
https://github.com/kubernetes/kubernetes/issues/104147
希望提供新的参数StrictCPUReservation,表示严格的预留资源,DefaultCPUSet列表会移除ReservedSystemCPUs.
- bug:释放init container的资源时,释放了重新分配给main container的资源。
https://github.com/kubernetes/kubernetes/issues/105114
这个issue已经修复:在RemoveContainer阶段,排除还在使用的容器的cpuset。剩下的cpuset才可以释放回DefaultCPUSet。
- 支持原地垂直扩展:针对已经部署到节点的pod实例,通过resize请求,修改pod的资源量。
https://github.com/kubernetes/enhancements/issues/1287
原地垂直扩展的意思是:当业务调整服务的资源时,不需要重启容器。
原地垂直扩容是个复杂的功能,这里大致介绍设计思路。详细实现可以看PR: https://github.com/kubernetes/kubernetes/pull/102884。
kube-scheduler依然使用pod的Spec…Resources.Requests来进行调度。依据pod的Status.Resize状态,判断缓存中node已经分配的资源量。
- Status.Resize = “InProgress” or “Infeasible”,依据Status…ResourcesAllocated(已经分配的值)统计资源量。
- Status.Resize = “Proposed”,依据Spec…Resources.Requests(新修改的值) 和 Status…ResourcesAllocated(已经分配的值,如果resize合适,kubelet也会将新requests更新这个属性),取两者的最大值。
kubelet侧的核心在admit阶段来判断剩余资源是否满足resize。而具体resize是否需要容器重启,需要依据container runtime来判断。所以这个resize功能其实是尽力型。通过ResizePolicy字段来判断:

还值得注意点是当前PR主要是在kata、docker上支持原地重启,windows容器还未支持。
有趣的社区提案
调度器拓扑感知调度
Redhat将他们实现的一套拓扑调度的方案贡献到社区:https://github.com/kubernetes/enhancements/pull/2787
扩展cpuManager防止理核不在容器间共享:
防止同一个物理核的虚拟分配带来的干扰。
设计文档里引入新参数cpumanager-policy-options:full-pcpus-only,期望分配独占一个物理cpu。当指定了full-pcpus-only参数以及static策略时,cpuManager会在分配cpusets会额外检查,确保分配cpu的时候是分配整个物理核。从而确保容器在物理核上的竞争。
具体例子比如,一个容器申请了5个独占核(虚拟核),cpu 0-4都分配个了服务容器。cpu 5也被锁住不能再分配给容器。因为cpu 5和cpu 4同在一个物理核上。

- 增加cpuMananger跨numa分散策略:distribute-cpus-across-numa
full-pcpus-only:上面已经描述:full-pcpus-only确保容器分配的cpu物理核独占 。distribute-cpus-across-numa:跨numa node 均匀分配容器。
开启distribute-cpus-across-numa时,当容器需要分配跨numa node时,statie policy会跨numa node平均分配cpu。非开启的默认逻辑是优选填满一个numa node。防止跨numa node分配时,在一个余量最小的numa node上分配。从整个应用性能考虑,性能瓶颈收到落在剩余资源较少的numa node上性能最差的worker(process?)。这个选项能够提供整体性能。
接下来介绍几个社区slack里讨论的几个提案:
- CPU Manager Plugin Model
- Node Resource Interface
- Dynamic resource allocation
CPU Manager Plugin Model
CPU Manager Plugin Model:kubelet cpuManager的插件框架。在不改动资源管理主流程前提下,支持不同的cpu分配场景。依据业务需求,实现更细粒度的控制cpuset。
kubelet在pod绑定成功之后,会将pod压入本地调度队列里,依次执行pod的cpuset的调度流程。调度流程本质上借鉴了kube-scheduler的调度框架。
插件可扩展点:
一个插件可以实现1个或多个可扩展点:
- Sort:将调度到节点上的pod排序处理。例如依据pod QoS判定的优先顺序。
- Filter:过滤无法分配给pod的cpu。
- PostFilter:当没有合适的cpu时,可以通过PostFilter进行预处理,然后将pod重新进行处理。
- PreScore:对于单个cpu评分,提供给后面流程来判定分配组合的优先级。
- Select:依据PreScore的结果选择一个cpu组合的最优解,最优解的结构是一组cpu。
- Score:依据Select的结果——cpu分配组合评分。
- Allocate:在分配cpuset之后,调用该插件。
- Deallocate:在PostFilter之后,释放cpu的分配。
三个评分插件的区别:
PreScore:返回以cpu为key,value为单个cpu对于pod容器的亲和程度。
Select:依据插件的领域知识(比如同一个numa的cpu分配结构聚合),将cpu组合的分数聚合。返回是一组最佳cpu。
Score:依据所有的cpu组合,评分分配组合依据插件强约束逻辑。
方案提出了两种扩展插件的方案。当前在kubelet的容器管理中,topologyManager主要完成下列事项:
- 调度用hintProvider,获得各个子管理域的可分配情况
- 编排整体的拓扑分配决策
- 提供“scopes”和policies参数来影响整体策略
其他子管理域的子manager(如cpuManager)作为hintProvider提供单个分配策略。在CPU Manager Plugin Model中,子manager作为模型插件接口提供原有功能。
方案1:扩展子manager,让topologyManager感知cpuset
通过当前的值回去numa node的分配扩展到能够针对单个cpuset的分配倾向。扩展插件以hint providers的形式执行,主流程不需要修改。
缺点:其他hintProvider(其他资源的分配)并不感知cpu信息,导致hintProvider的结果未参考cpu分配。最终聚合的结果不一定是最优解。
方案2:扩展 cpuManager为插件模型
topologyManager依然通过GetTopologyHints()和Allocate() 调用cpuManager,cpuManager内部进行扩展调度流程。具体的扩展方式可以通过引入新的policy配置,或者通过调度框架的方式直接扩展。
缺点:cpuManager的结果并不决定性的,topologyManager会结合其他hints来分配。
可以看到CPU Manager Plugin Model当前提案还出于非常原始的阶段,主要是Red Hat的人在推。并未在社区充分讨论。
Node Resource Interface
该方案来自containerd。主要是在CRI中扩展NRI插件。
containerd
containerd主要工作在平台和更底层的runtime之间。平台是指docker、k8s这类容器平台,runtime是指runc, kata等更底层的运行时。containerd在中间提供容器进程的管理,镜像的管理,文件系统快照以及元数据和依赖管理。下图是containerd架构总览图:
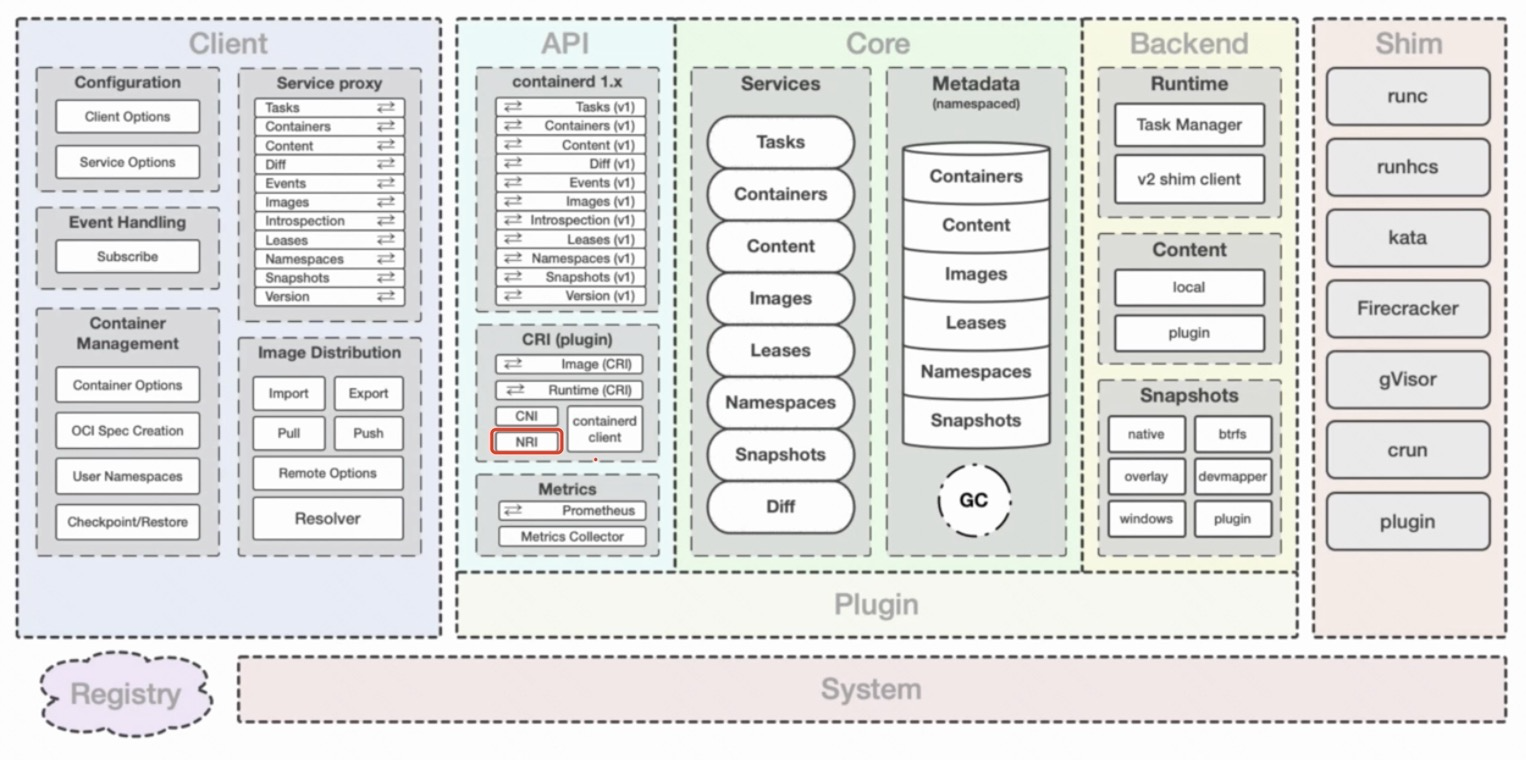
client是用户交互的第一层,提供接口给调用方。
core定义了核心功能接口。所有的数据都通过core管理存储(metadata store),所有其他组件/插件不需要存储数据。
backend中的runtime负责通过不同shim与底层runtime打交道。
api层主要提供两大类gRPC 服务:image,runtime。提供了多种插件扩展。
在CRI这一层,包含了CRI、CNI、NRI类型的插件接口:
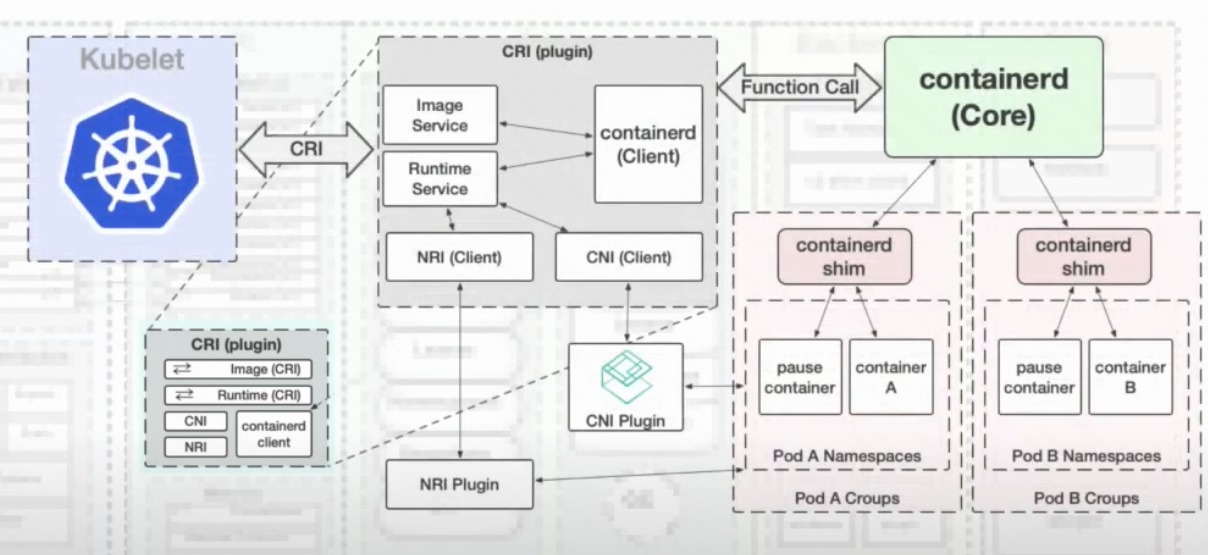
- CRI plugin:容器运行时接口插件,通过共享namespace、cgroups给pod下所有的容器,负责定义pod。
- CNI plugin:容器网络接口插件,配置容器网络。当containerd创建第一个容器之后,通过namespace配置网络。
- NRI plugin:节点资源接口插件,管理cgroups和拓扑。
NRI
NRI位于containerd架构中的CRI插件,提供一个在容器运行时级别来管理节点资源的插件框架。
cni可以用来解决批量计算,延迟敏感性服务的性能问题,以及满足服务SLA/SLO、优先级等用户需求。例如性能需求通过将容器的cpu分配同一个numa node,来保证numa内的内存调用。当然除了numa,还有CPU、L3 cache等资源拓扑亲和性。
当前kubelet的实现是通过cpuManager的处理对象只能是guaranteed类的pod, topologyManager通过cpuManager提供的hints实现资源分配。
kubelet当前也不适合处理多种需求的扩展,因为在kubelet增加细粒度的资源分配会导致kubelet和CRI的界限越来越模糊。而上述CRI内的插件,则是在CRI容器生命周期期间调用,适合做resoruce pinning和节点的拓扑的感知。并且在CRI内部做插件定义和迭代,可以做到上层kubernetes以最小代价来适配变化。
在容器生命周期中,CNI/NRI插件能够注入到容器初始化进程的Create和Start之间:
Create->NRI->Start
以官方例子clearcfs:在启动容器前,依据qos类型调用cgroup命令,cpu.cfs_quota_us 为-1 表示不设上限。
可以分析出NRI直接控制cgroup,所以能有更底层的资源分配方式。不过越接近底层,处理逻辑的复杂度也越高。
Dynamic resource allocation
KEP里翻到了这个动态资源分配,方案提供了一套新的k8s管理资源和设备资源的模型。核心思想和存储类型(storageclass)类似,通过挂载来实现具体设备资源的声明和消费,而不是通过request/limit来分配一定数量的设备资源。
用例:
- 设备初始化:为workload配置设备。基于容器需求的配置,但是这部分配配置不应该直接暴露给容器。
- 设备清理:容器结束后清理设备参数/数据等信息.
- Partial allocation:支持部分分配,一个设备共享多个容器。
- optional allocation:支持容器声明软性(可选的) 资源请求。例如:GPU and crypto-offload engines设备的应用场景。
- Over the Fabric devices:支持容器使用网络上的设备资源。
动态资源分配的设计目的是提供更灵活控制、用户友好的api,资源管理插件化不需要重新构建k8s 组件。
通过定义动态资源分配的资源分配协议和gRPC接口来管理新定义k8s资源 ResourceClass和ResourceClaim:
- ResourceClass指定资源的驱动和驱动参数
- ResourceClaim指定业务使用资源的实例
立即分配和延迟分配:
- 立即分配:ResourceClaim创建时就分配。对于稀缺资源的分配能够有效使用(allocating a resource is expensive)。但是没有保障由于其他资源(cpu,内存)导致节点无法调度。
- 延迟分配:调度成功才分配。能够处理立即分配带来的问题。
调用流程

- 用户创建 带有resourceClaimTemplate配置的pod。
- 资源声明 controller创建resourceClaim。
- 依据resourceClaim的spec中,立即分配(immediate allocation)和延迟分配(delayed allocation)处理。
- 立即分配:资源驱动controller发现resourceClaim的创建时并claim。
- 延迟分配:调度器首先处理,过滤不满足条件的节点,获得候选节点集。资源驱动再过滤一次候选节点集不符合要求的节点。
- 当资源驱动完成资源分配之后,调度器预留资源并绑定节点。
- 节点上的kubelet负责pod的执行和资源管理(调用驱动插件)。
- 当pod删除时,kubelet负责停止pod的容器,并回收资源(调用驱动插件)。
- pod删除之后,gc会负责相应的resourceClaim删除。
这块文档没有具体描述:在立即分配的场景中,如果没有调度器工作,resoruce driver controller来节点选择机制是怎么样的。
总结
可以看到未来社区会对kubelet容器管理做一次重构,来支持更复杂的业务场景。近期在cpu资源管理上会落地的调度器拓扑感知调度,和定制化的kubelet cpu分配策略。在上述的一些case中,有发展潜力的是NRI方案。
- 支持定制化扩展,kubelet可以直接载入扩展配置无需修改自身代码。
- 通过与CRI交互,kubelet将部分复杂的cpu分配需求下放到runtime来处理。
参考文档
CPU Management Kubelet Use Cases & Current State: https://docs.google.com/document/d/1U4jjRR7kw18Rllh-xpAaNTBcPsK5jl48ZAVo7KRqkJk/edit
NRI:https://github.com/containerd/nri
Dynamic resource allocation KEP:https://github.com/kubernetes/enhancements/pull/3064