资源拓扑感知调度方案
之前文章分析过Volcano的NUMA拓扑资源调度的设计,这次扒一扒社区scheduling sig设计的一种方案。这个方案由Red Hat主导,通过两个组件实现资源拓扑感知调度。一个是worker node上报拓扑资源状态的agent:这个功能可以由Node feature Discovery (NFD)或者Resource Topology Exporter (RTE) 实现;一个是扩展调度功能的scheduler-plugin,通过扩展调度器的filter/score扩展点来实现资源拓扑感知。
NFD和RTE都是一个Red Hat的团队实现的。我们先了解下NFD,再重点分析RTE的实现。NFD依赖RTE中的NodeResourceTopology CR上报节点资源信息。但是RTE可以独立工作。
NFD由两个组件组成:nfd-master 和 nfd-worker。nfd-master 负责将节点的信息标记到节点对象上。对于的节点label上会增加如下信息:
$ kubectl get node -ojson | jq .items[].metadata.labels
{
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/os": "linux",
"feature.node.kubernetes.io/cpu-cpuid.ADX": "true",
"feature.node.kubernetes.io/cpu-cpuid.AESNI": "true",
...
nfd-worker负责在节点上将节点拓扑信息通过grpc上报给nfd-master。nfd-worker会上报机器的内核信息、cpu信息等。当需要上报节点的资源拓扑信息时,nfd会在节点以daemonSet的形式部署topologyUpdater模块,该模块负责机器资源的拓扑信息(比如numa node上的cpu分配状态)。
NFD和RTE两者对于节点的资源拓扑信息上报的差别在于:
NFD通过topologyUpdater上报给nfd-master,topologyUpdater只负责机器资源的拓扑信息。
RTE通过Resource Topology Exporter直接更新节点的NodeResourceTopology数据。
我们重点看看Resource Topology Exporter的设计思想。
资源拓扑上报
RTE负责上报节点的资源,以daemonSet的形式在每个节点上执行。该组件收集节点上的pod的分配资源和资源拓扑信息(NUMA nodes),并通过NodeResourceTopology CRD更新节点拓扑数据,调度器kube-scheduler依据每个节点的NodeResourceTopology数据来感知节点侧的拓扑策略和资源拓扑状态。
首先,RTE通过节点上kubelet的podresources接口(通过 /var/lib/kubelet/pod-resources/kubelet.sock 获取kubelet的相关数据)获取pod的资源分配信息获取pod的资源分配信息,包括设备的拓扑信息。这部分暴露podresources的功能需要在k8s版本v1.20+上正式GA。
此外,RTE有个与podresources相关的reference-container参数。因为接口返回的数据没有区分绑核信息。当前pod resources的List接口返回的容器分配的cpu #,不区分共享池和独占池的cpu分配情况。所以对于请求值不为整数的Guaranteed pod,List会返回共享池的cpu #。但在资源充足的情况下,非独占池的cpu都是可以分配给有绑核需求的实例。
- 相应的社区修复pr:接口剔除共享池的分配信息:https://github.com/kubernetes/kubernetes/pull/97415
RTE在现有接口的条件下,通过创建一个pause container来获得共享池的cpu ids。在统计时,再将reference-container的cpu #(共享池)信息来过滤接口返回的数据,这样得到的结果就只包含独占的cpu #。
RTE有resourceObserver和NRTUpdater模块负责生成和上传NodeResourceTopology。
resourceObserver
resourceObserver通过resourceMonitor获取节点的资源拓扑信息并发送到channel。resourceMonitor监听本地容器CRI的资源分配和kubelet变化。当监听文件变化时,resourceMonitor扫描机器上的容器资源分配情况。
首先,通过/sys/devices目录下的信息,更新节点numa node的容量和可分配量:
cpu资源通过ghw包来发现(https://github.com/jaypipes/ghw)。(/sys/devices/system/node/nodeX/cpuX ),这里的cpuX是逻辑id。core_id在/sys/devices/system/node/node0/cpu10/topology/core_id
内存资源则是nte扩展。比如hugepages会读取numa node信息(/sys/devices/system/node/node0/hugepages),比如下图展示node0的数据。通过获取nr_hugepages的值(0表示HugePages 未启用,其他值表示HP总数)。内存量则读取numa node的meminfo文件(/sys/devices/system/node/node0/meminfo)的MemTotal值。

然后通过kubelet的podresources接口,获取分配给pod的容器的资源量。如下例所示,接口会返回每个容器的cpu、设备分配信息。
&v1.ListPodResourcesResponse{
PodResources: []*v1.PodResources{
{
Name: "test-pod-0",
Namespace: "default",
Containers: []*v1.ContainerResources{
{
Name: "test-cnt-0",
CpuIds: []int64{5, 7},
Devices: []*v1.ContainerDevices{
{
ResourceName: "fake.io/net",
DeviceIds: []string{"netBBB"},
Topology: &v1.TopologyInfo{
Nodes: []*v1.NUMANode{
{
ID: 1,
},
},
},
},
},
},
},
},
},
}
最后将这两部分数据聚合到Zone结构里。resourceMonitor将每个NUMA node封装成一个Zone,Zone未来也会支持socket,die,core等拓扑信息。
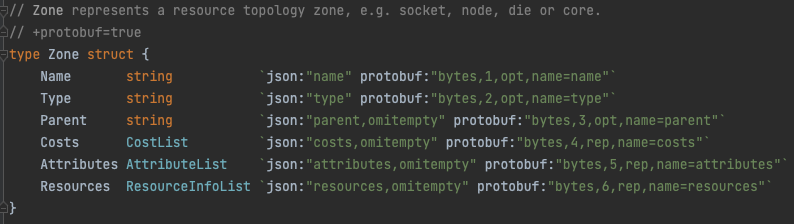
对于numa node,type为"Node"。costs数组包含node之间的访问成本。resources字段记录每个numa node各资源的容量(capacity),可分配量(allocatable),可用量(available=allocatable-从pod resources接口获得的绑核独占资源)。其他字段目前没有实际含义。
最后resourceMonitor将所有的numa node资源信息通过事件发送消费者NRT Updater模块。
NRT Updater
NRTUpdater通过resourceObserver传递的channel拿的更新的资源拓扑数据,主要工作也就是将数据更新到对应的NodeResourceTopology CRD。
CRD API的定义: https://github.com/k8stopologyawareschedwg/noderesourcetopology-api
// NodeResourceTopology is a specification for a NodeResourceTopology resource
type NodeResourceTopology struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
TopologyPolicies []string `json:"topologyPolicies"`
Zones ZoneList `json:"zones"`
}
// Zone is the spec for a NodeResourceTopology resource
type Zone struct {
Name string `json:"name"`
Type string `json:"type"`
Parent string `json:"parent,omitempty"`
Costs CostList `json:"costs,omitempty"`
Attributes AttributeList `json:"attributes,omitempty"`
Resources ResourceInfoList `json:"resources,omitempty"`
}
type ZoneList []Zone
type ResourceInfo struct {
Name string `json:"name"`
Allocatable intstr.IntOrString `json:"allocatable"`
Capacity intstr.IntOrString `json:"capacity"`
}
type ResourceInfoList []ResourceInfo
type CostInfo struct {
Name string `json:"name"`
Value int `json:"value"`
}
type CostList []CostInfo
type AttributeInfo struct {
Name string `json:"name"`
Value string `json:"value"`
}
type AttributeList []AttributeInfo
CRD的关键数据结构有TopologyPolicies反映节点的拓扑策略和Zones反映节点资源拓扑单位,其他字段目前对调度无实义。
- TopologyPolicies:拓扑策略,可选值: None, BestEffort, Restricted, SingleNUMANodePodLevel,SingleNUMANodeContainerLevel。
依据kubelet的2个参数:topologyManagerPolicy,topologyManagerScope的两个参数组合来判断。RTE的同名参数优先级高于kubelet的优先级。两个参数的可选值为:
- topologyManagerPolicy:
// - `restricted`: kubelet only allows pods with optimal NUMA node alignment for
// requested resources;
// - `best-effort`: kubelet will favor pods with NUMA alignment of CPU and device
// resources;
// - `none`: kublet has no knowledge of NUMA alignment of a pod's CPU and device resources.
// - `single-numa-node`: kubelet only allows pods with a single NUMA alignment
// of CPU and device resources.
- topologyManagerScope:
// - `container`: topology policy is applied on a per-container basis.
// - `pod`: topology policy is applied on a per-pod basis.
RTE依据topologyManagerPolicy判断TopologyPolicies为None, BestEffort, Restricted, SingleNUMANode类型,特殊的在single-numa-node的情况下会结合topologyManagerScope映射成对应的分配策略:
- SingleNUMANodeContainerLevel:表示{topologyManagerPolicy: single-numa-node, topologyManagerScope: container}
- SingleNUMANodePodLevel:表示{topologyManagerPolicy: single-numa-node, topologyManagerScope: pod}
- Restricted:表示{topologyManagerPolicy: restricted}
- BestEffort:表示{topologyManagerPolicy: best-effort}
- None:表示{topologyManagerPolicy: none}
- Zones:list,等于resourceObserver构造的zones,代表一个资源的拓扑空间信息,例如socket, node, die or core(这里的node就是NUMA node)。
- Name:名称,numa node为node id加上node-前缀
- Type:类型,numa node为“Node”
- Resources:资料类型、capacity(总量)、allocatable(可分配量)、available(可使用量)等值。
通过在集群创建包含节点拓扑策略和资源拓扑信息的NodeResourceTopology,使得集群内组件能够感知节点侧的资源拓扑情况。调度器通过节点资源拓扑数据来选择。
调度感知
依据依据topologyPolicies的值,计算不同范围的资源拓扑状态,调度决策。目前只支持下面两个single-numa-node策略下的container级别或者pod级别的。
SingleNUMANodeContainerLevel:以pod的单个容器为单位计算。
SingleNUMANodePodLevel:会将pod的所有容器(init/normal)加在一起计算。
- Filter
SingleNUMANodePodLevel是需要pod的所有容器都适配拓扑策略,SingleNUMANodeContainerLevel是确保每个容器单独适配拓扑策略。所以第一步是依据这个逻辑计算检验pod资源需求。
遍历节点上的每个numa node,如果Resources没有调度pod的请求的资源类型,则忽略numa node(节点的可用资源满足的前提下)。
然后判断下列4种条件只要一个为真则表示numa node可以分配给实例:
- pod的资源类型是内存/hugepages,因为当前方案还未支持memory manager
- pod的资源类型为cpu,并且pod不为guaranteed。因为非guaranteed的pod的cpu的分配会变化。
- pod的资源请求量为0
- numa node的资源量满足pod的请求量
如果可用则添加到资源位掩码bitmask中,bitmask上的每一位代表一个numa node。bit置1则表示numa node上的资源满足需求。最后取每个资源类型的numa结果的与集为节点最终结果。如果结果为空则表示节点没有numa node满足container/pod的需要。
特殊情况下,节点会直接返回可调度的结构:pod的QoS为BestEffort,节点没有NodeResourceTopology crd数据。
- Score
依据score算法(MostAllocated/BalancedAllocation/LeastAllocated)决定权开启NUMA 亲和的节点优先级。三种策略依据单numa node上的单资源类型评分,依据全局配置的资源权重算出单numa node对于容器(或pod)的评分:
- MostAllocated:请求量/剩余可分配量(available),即分配率约高,分数越高。依权重计算总和。
- BalancedAllocation:首先计算每个资源的请求量/剩余可分配量(available),依据(1-分配率方差)计算numa node的分数。各资源类型分配率的离散程度越低,分数越高。
- LeastAllocated:(剩余可分配量-请求量)/剩余可分配量,即分配率约低,分数越高。依权重计算总和
第一步和filter类似,也会依据scope计算pod的所需资源量。pod scope会计算pod的容器资源综合,container scope会计算各容器评分的均值。
然后计算节点侧的资源状态,获得每个numa node的剩余可分配资源。
特殊情况下,节点会直接返回表示最低优先级零分:节点没有NodeResourceTopology crd,或者节点的TopologyPolicies为空。
总结
这套方案依据节点拓扑状态调度,补足了原生调度器的缺陷。对比volcano的方案,也更加清晰简洁。调度器感知的节点资源状态,尽量与节点侧一致。但是通过分析发现还有如下不足:
没有区分需要拓扑亲和的pod和普通的pod,容易造成开启拓扑功能的节点高优资源浪费。在调度拓扑敏感性的应用时,重新分配已被低QoS实例的拓扑资源。已运行的实例从单numa node退化成跨numa node,造成性能抖动。
调度器没有资源预留,同一份numa node的资源存在被多个实例竞争的风险。在调度侧确认候选节点到节点侧实际分配资源以及更新到CRD之间,已经分配的numa node在调度侧应该可以被重新计算。方案通过选择评分最小的numa node来规避这个问题,但是没有本质上解决这个问题。
没有精细化处理pod QoS类型。对于QoS为burstable,节点侧的资源分配是依据资源Limits。这个方案容易造成机器资源的竞争。
参考
- 社区资源拓扑kep: https://github.com/kubernetes-sigs/scheduler-plugins/blob/v0.22.6/pkg/noderesourcetopology/README.md
- RTE repo: https://github.com/k8stopologyawareschedwg/resource-topology-exporter
- NFD repo: https://github.com/kubernetes-sigs/node-feature-discovery
- pod resources rep: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2043-pod-resource-concrete-assigments/README.md