多集群调度
Kubernetes是一个容器编排平台,用于调度、部署和管理容器化应用。并且经过几年的发展,k8s已经成为事实上的容器编排平台标准。集群是k8s架构的构建块(building block)。集群由多个工作节点(物理机或者虚拟机)组成,提供一个可供容器运行的资源池。一个集群拥有:
- 一个单独的API入口
- 一个集群范围的资源命名组织结构
- 一个调度域
- 一个服务路由域
- ……
每个集群都是独立的系统,可以部署在公司的自建机房,也可以部署在云厂商的一个可用区。k8s负责管理集群的可用资源:调度器将容器调度到适当的机器、kubelet负责pod/容器的生命周期管理。这些都是大家很熟悉的概念了。但是k8s的作用范围是集群内,一个集群内的控制平面无法感知另一个集群的资源余量和服务状态。当多集群的应用场景出现时,我们怎么处理多个集群的调度呢。
为什么要有多集群调度?
通常来说,一个集群的大小需要预估业务的资源总量。当资源不够时,可以通过增加机器数量来进行集群扩容。但是集群规模也不是无限上升的。当节点/pod的数量越多,对控制平台的组件的压力就越大,进而影响集群整体稳定性。
- 单集群的容量限制:单集群的最大节点数不是一个确定值,其受到集群的部署方法和业务使用集群资源的方式的影响。在官方文档中的集群注意事项里提到单集群5000个节点上限,我们可以理解为推荐最大节点数。
- 多租户:因为容器没法做到完美的隔离,不同租户可以通过不同宿主机或者不同集群分割开。对企业内部也是如此,业务线就是租户。不同业务线对于资源的敏感程度也不同,企业也会将机器资源划分为不同集群给不同业务线用。
- 云爆发:云爆发是一种部署模式,通过公有云资源来满足应用高峰时段的资源需求。正常流量时期,业务应用部署在有限资源的集群里。当资源需求量增加,通过扩容到公有云来消减高峰压力。
- 高可用:单集群能够做到容器级别的容错,当容器异常或者无响应时,应用的副本能够较快地另一节点上重建。但是单集群无法应对网络故障或者数据中心故障导致的服务的不可用。跨地域的多集群架构能够达到跨机房、跨区域的容灾。
- 地域亲和性:尽管国内互联网一直在提速,但是处于带宽成本的考量,同一调用链的服务网络距离越近越好。服务的主调和被调部署在同一个地域内能够有效减少带宽成本;并且分而治之的方式让应用服务本区域的业务,也能有效缓解应用服务的压力。
当然,使用多集群调度肯定会增加整体架构的复杂度,集群之间的状态同步也会增加控制面的额外开销。所以,多集群的主要攻克的难点就是跨集群的信息同步和跨集群网络连通方式。跨集群网络连通方式一般的处理方式就是确保不同机房的网络相互可达,这也是最简单的方式。
而我比较干兴趣的是跨集群的信息同步。多集群的服务实例调度,需要保证在多集群的资源同步的实时,将pod调度不同的集群中不会pod pending的情况。控制平面的跨集群同步主要有两类方式:
- 定义专属的API server:通过一套统一的中心化API来管理多集群以及机器资源。KubeFed就是采用的这种方法,通过扩展k8s API对象来管理应用在跨集群的分布。
- 基于Virtual Kubelet:Virtual Kubelet本质上是允许我们冒充Kubelet的行为来管理virtual node的机制。这个virtual node的背后可以是任何物件,只要virtual node能够做到上报node状态、和pod的生命周期管理。Liqo就是通过定制的virtual kubelet来实现多集群管理。
| 场景 | Kubefed | Liqo |
|---|---|---|
| Pod调度 | 静态调度、动态调度只支持Deployment/ReplicaSet | 动态调度,但是还是会出现pending情况 |
| 控制平面 | 一套中心化管理组件 | 每个集群对等管理 |
| 集群发现 | 主动注册 | 动态发现和注册新集群 |
本文不会详细介绍这些项目在部署和网络管理的内容,重点分析两个项目(Kubefed、Liqo)的跨集群资源调度。
KubeFed
KubeFed的目的是通过统一的API管理多个k8s集群,实现单一集群管理多个k8s集群的机制,并通过CRD的机制来扩展现有的k8s资源跨集群编排的能力。
KubeFed将集群分为host cluster,member cluster两个角色:
- host cluster:KubeFed的控制平面面,用户需要安装KubeFed的operator组件。
- member cluster:注册到KubeFed API上的集群,由KubeFed统一管理。通过命令行
kubefedctl join的方式手动注册到host cluster。
被联邦管理的k8s API资源统称为Federated Resources,例如FederatedDeployments。开启跨集群调度也需要在host cluster上显式地对应用资源开启集群联邦管理,开启的方式是通过kubefedctl federate创建FederatedTypeConfig。KubeFed也支持联邦化namespace,让namespace下面的资源都联邦化。通过federation control plane来下发资源到member cluster。
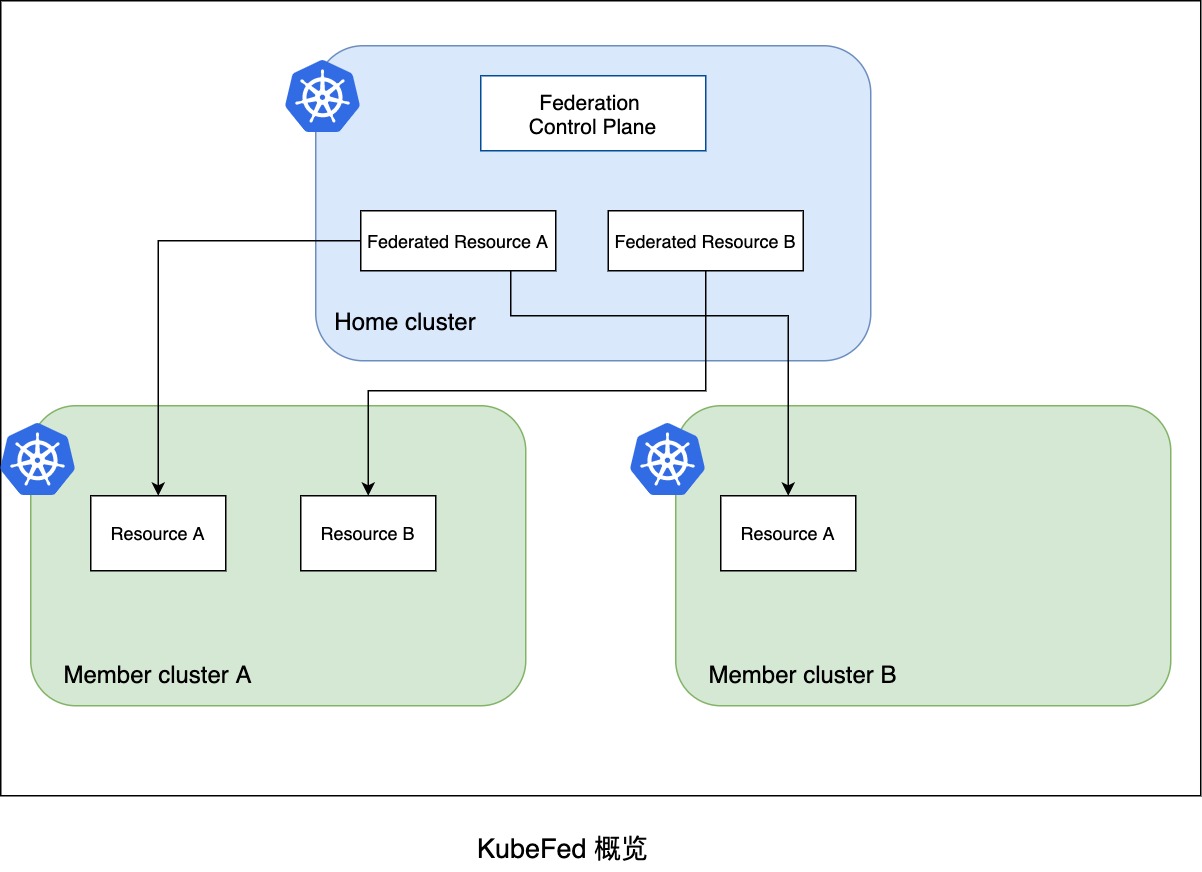
资源调度
那KubeFed怎么支持跨集群部署的呢?在开启资源的联邦化之后,Federated Resources的spec分成3个基础配置:
- template:原资源类型的spec
- placement:定义期望部署的集群
- overrides:定义集群特定配置,基于原资源类型的spec进行修改,比如副本数的变化
用户在部署服务时,可以在spec下定义部署的集群(placement)和集群指定参数(overrides)。比如服务需要在cluster2集群上增加副本数,修改deployment的replicas,需要在overrides上填写“/spec/replicas”的修改。可以想到为了通用,overrides的配置有一定复杂性。
spec:
template:
metadata:
labels:
app: nginx
spec:
replicas: 3
...
placement:
clusters:
- name: cluster2
- name: cluster1
overrides:
- clusterName: cluster2
clusterOverrides:
- path: "/spec/replicas"
value: 5
...
Federated Resources还支持通过另一个CRD来ReplicaSchedulingPreference配置资源类型级别的集群调度倾向。该方法通过指定资源类型在member cluster的最大/最小副本数实现了依据剩余可用资源的动态平衡。最终controller会将preference信息更新到Federated Resources的overrides上,从而重新分配实例。不过该功能还只支持deployment/replicaset资源。
可以看出在KubeFed的架构,还是区分了不同集群的配置和动态调度。
具体看看静态调度和动态调度。
静态调度
首先,FederatedTypeConfig的spec里定义了host cluster中的Federated Resources和member cluster集群的所代表的资源:
- federatedType 定义在host cluster在多集群中的状态的API资源类型(由用户创建)
- targetType 定义在member cluster集群代表Federated Resources的API资源类型(由controller创建)
- statusType 用来更新federated resource的状态(由controller创建,默认为federatedType)
spec 对应的 federatedType 是定义的联邦资源(由用户创建),而 targetType 实际上是真正的k8s workload 资源, KubeFed的controller可以通过 federatedType的placement和overrides 来控制各个集群里的对应的 targetType 的资源的分布。具体来说,负责下发targetType的SyncController会调用dispatcher生成JSONPatch并向member cluster创建底层资源。
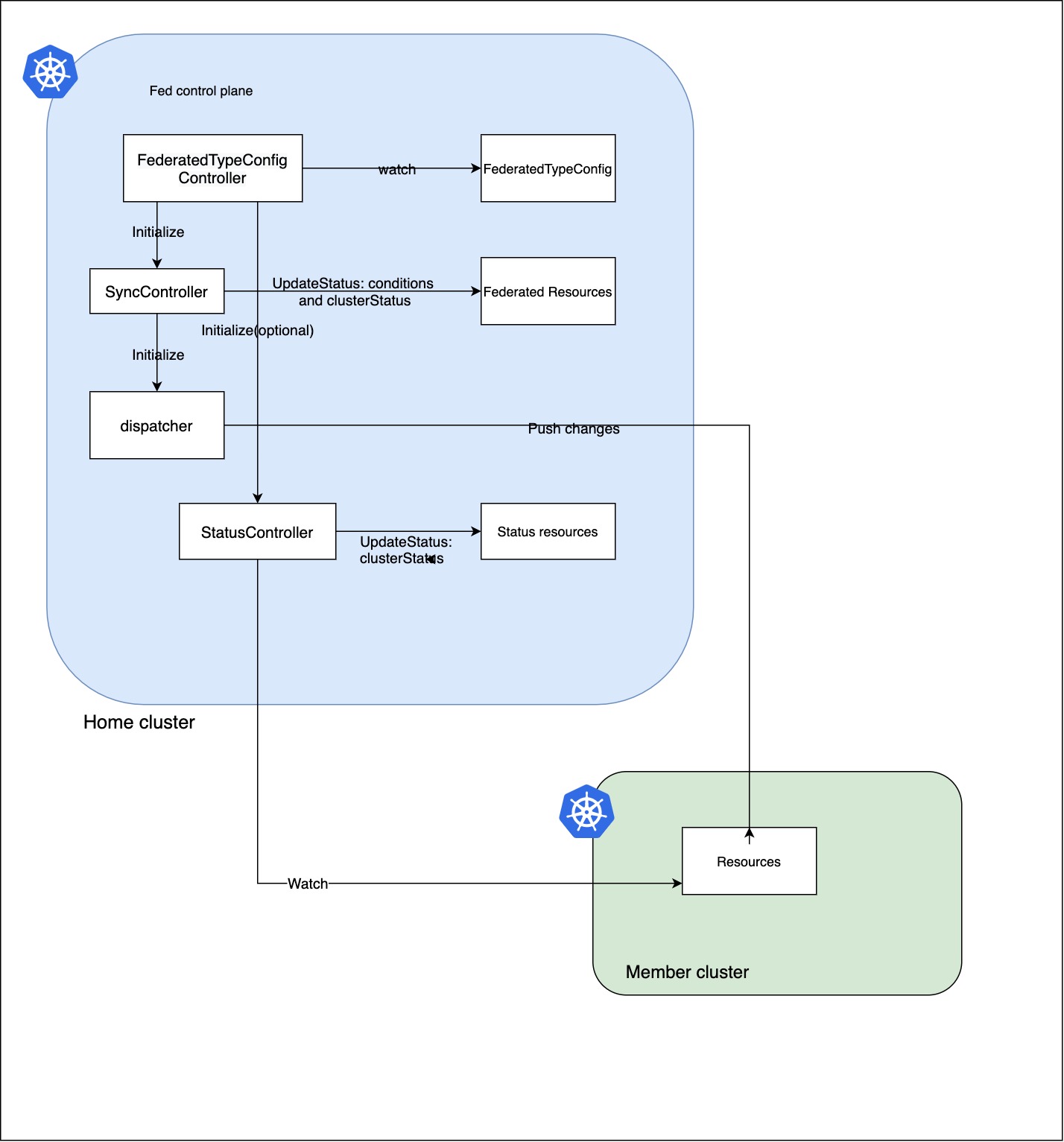
默认创建Federated资源时,可以在spec下定义部署的集群(placement)和集群指定参数(overrides),实现多集群的pod分配。但是这种调度是静态的。如果overrides设置的副本数超过集群剩余可用资源,那么新pod在集群里因为资源不够导致pending。静态方式在大规模场景下无非是低效的,扩集群调度在极端情况下需要人工观测集群剩余资源来规划集群分布。但是很多服务是不需要感知集群信息的,他最在意的是还是服务实例能够正常启动,希望服务在不同集群的打散是一种动态被平台托管的。所以KubeFed引入了ReplicaSchedulingPreference(RSP)的功能。
RSP的实现依赖于一个新的CRD——ReplicaSchedulingPreference关键的几个配置项为:
- totalReplicas:期望的副本数
- rebalance:是否允许已调度的副本被重新平衡
- intersectWithClusterSelector:是否结合Fed Resources的placement下定义的集群结合
- clusters:定义各集群期望的最大最小副本数,以及分配权重
例如,下面这个例子期望cluster1和cluster2以2:3的比例下发服务的副本。当集群资源充足时,cluster1会分配4个pod,cluster2被分配6个实例。当集群cluster2资源不足时,rebalance的设置允许将cluster2的副本挪到cluster1。
spec:
targetKind: FederatedDeployment
totalReplicas: 10
rebalance: true
intersectWithClusterSelector: false
clusters:
cluster1:
weight: 2
cluster2:
weight: 3
下图描述了KubeFed RSP的工作流程,起作用的组件是ReplicaScheduler。
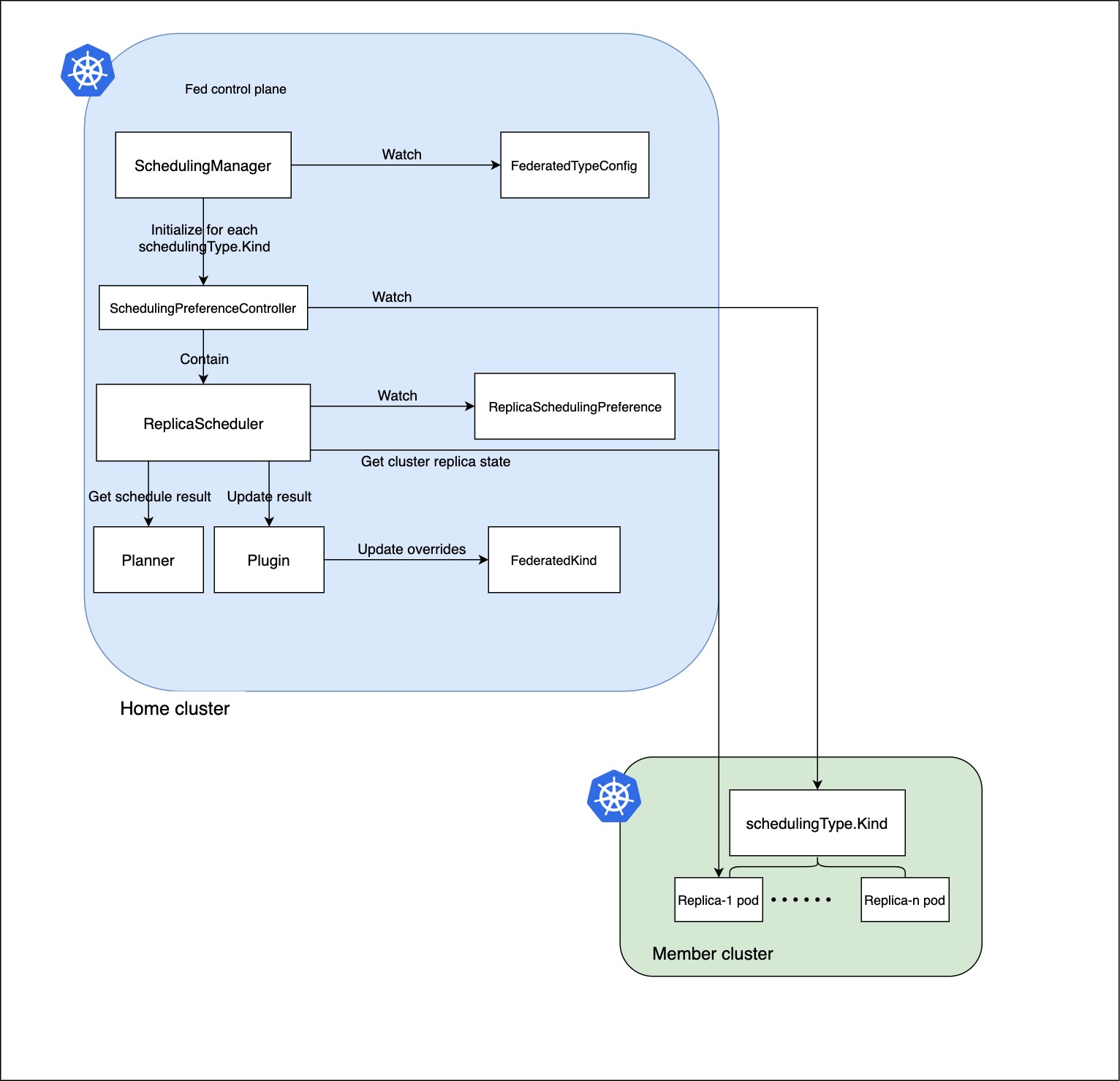
ReplicaScheduler首先会获取PreferredClusters,将健康的集群的信息收集。然后获取当前服务副本的集群分布,会统计每个集群的currentReplicasPerCluster、estimatedCapacity:
- currentReplicasPerCluster:集群内running并且ready的pod数量
- estimatedCapacity:期望的副本数spec.replicas - unschedulable的pod数量
ReplicaScheduler.Planner依据上述信息(RSP的spec、currentReplicasPerCluster和estimatedCapacity),在可用集群中分配副本。Planner的第一步会依据ReplicaSchedulingPreference中集群权重将可用集群排序,并划定每个集群的可分配上界和下界:
- 下界:从RSP的minReplicas和totalReplicas(totalReplicas累减)、estimatedCapacity,三值中选择最小的值作为每个集群的分配下界。
- 上界:如果rebalance未开启:首先在currentReplicasPerCluster的数量、estimatedCapacity和RSP的maxReplicas选择最小值,作为集群可用数量的增量,每个集群的上界是 下界+增量。
最终依据集群权重,将副本分配到各集群中。
ReplicaScheduler.Plugin获得新的overrides信息将原Federated resources的spec更新。之后的流程就是原有静态调度负责下发到集群。整个ReplicaSchedulingPreference能够动态地在多个集群分配pod,并且包含了处理Pending Pod的情况。
但是局限在于只支持Deployment/ReplicaSet资源。
Liqo
与KubeFed相比,Liqo有着pod无缝调度、去中心化治理等优势。
去中心化管理:采用P2P的对等管理,减少中心化管理组件。
无缝调度:创建用户服务资源时,和单集群操作一致。
Liqo将集群划分为home cluster和foreign cluster。在每个集群都需要安装liqo的组件来管理多集群,这两类集群本质上没有区别。只是对于home cluster来说,其他的foreign cluster都是通过Virtual Kubelet 的方式映射成本集群节点。home cluster将foreign cluster当作一个大的节点来使用。这样就能做到用户在home cluster上创建资源时,能够调度到foregin cluster上。Virutal Kubelet具体的内容可以看这篇文章《Virtual Kubelet》。Virutal Kubelet依据目的实现如下功能,就能在k8s集群内注册一个虚拟的节点。
自定义的provider必须提供以下功能:
- 提供pod、容器、资源的生命周期管理的功能
- 符合virtual kubelet提供的API
- 不直接访问k8s apiserver,定义获取数据的回调机制,例如configmap、secrets
在集群注册方面,Liqo支持动态发现集群(mDNS、LAN两种方式)。在安装Liqo组件时,可配置集群通过何种方式发现和集群共享出去的资源百分比(默认30%)。所以Liqo的多集群前提是集群之间已经网络可达。
Ligo 调度
在调度方面,因为remote cluster通过virtual kueblet将该集群视为一个大节点,可以直接依赖本集群的kube-scheduler来调度。但是这里还是有个问题。当remote cluster的资源碎片比较多时,大节点上报资源时会聚合成一个大块资源。导致大套餐的pod调度到remote cluster会出现pending。
Ligo的工作流程如下图所示.当用户创建一个deployment时,默认调度器负责判断能否调度到virtual node上。之后这个服务的pod创建会被virtual kubelet接管。当pod被调度的virtual node上时,virtual kubelet会在remote cluster会对应的replicaSet。使用replicaSet原因是remote cluster上的pod被驱逐时,能够在集群上重建,而不是在home cluster重新调度。
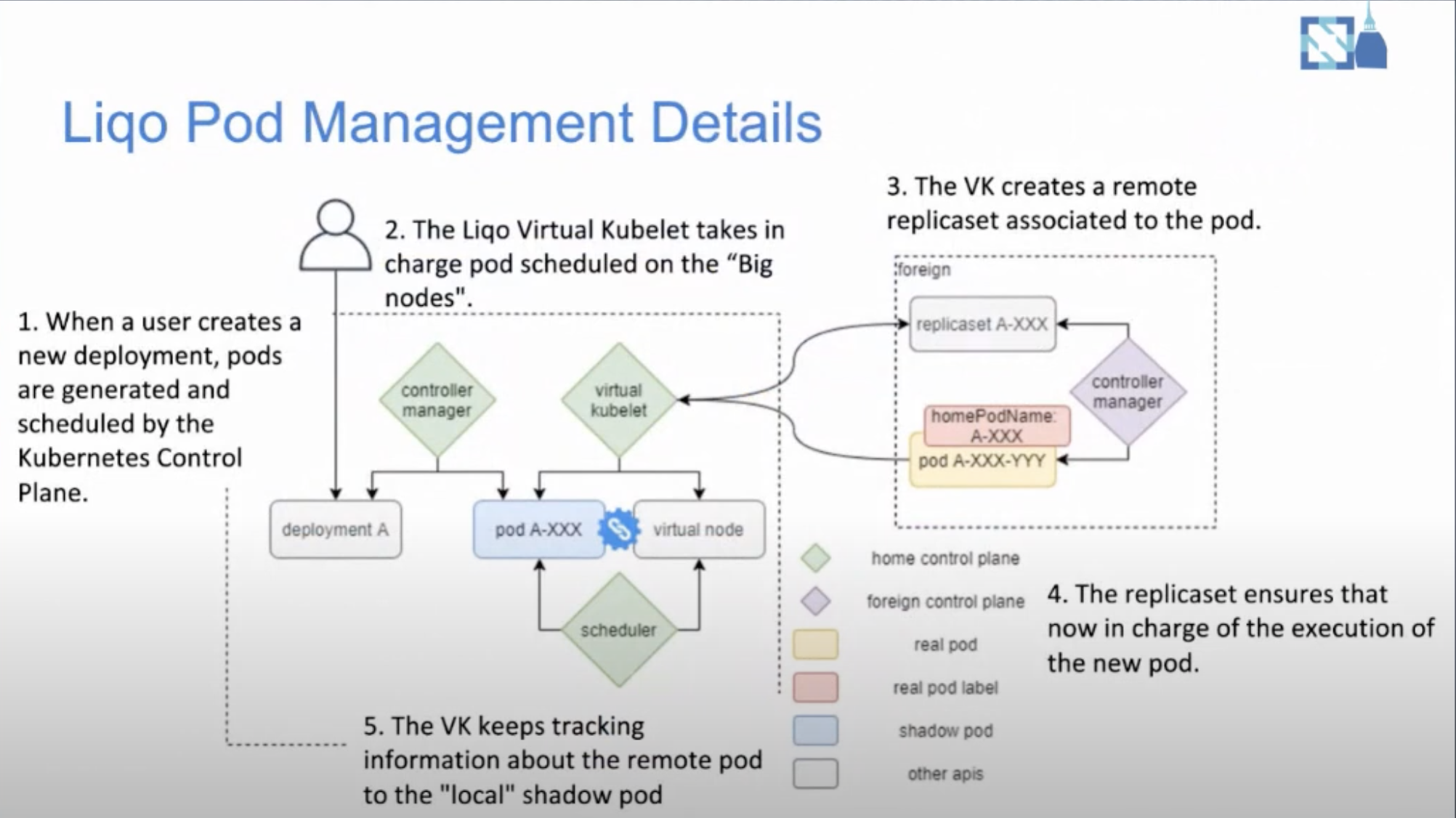
在了解多集群调度的细节之前,需要先弄清楚virtual kubelet的工作机制。我们知道Kubelet有个SyncHandler, virtual kubelet也有PodLifecycleHandler,处理pod被k8s创建、更新、删除的情况。例如,Liqo的virtual kubelet处理创建pod时,会先将pod的元数据里包含home cluster的信息转换成foreign cluster (比如label和namespace),然后将pod包在ReplicaSet里通过foreign Client创建ReplicaSet资源。
上面介绍了一个pod在不同集群之间的映射。接下来从foreign cluster的角度发现home cluster的共享资源的具体流程。下属Controller和CRD都是由Liqo安装。
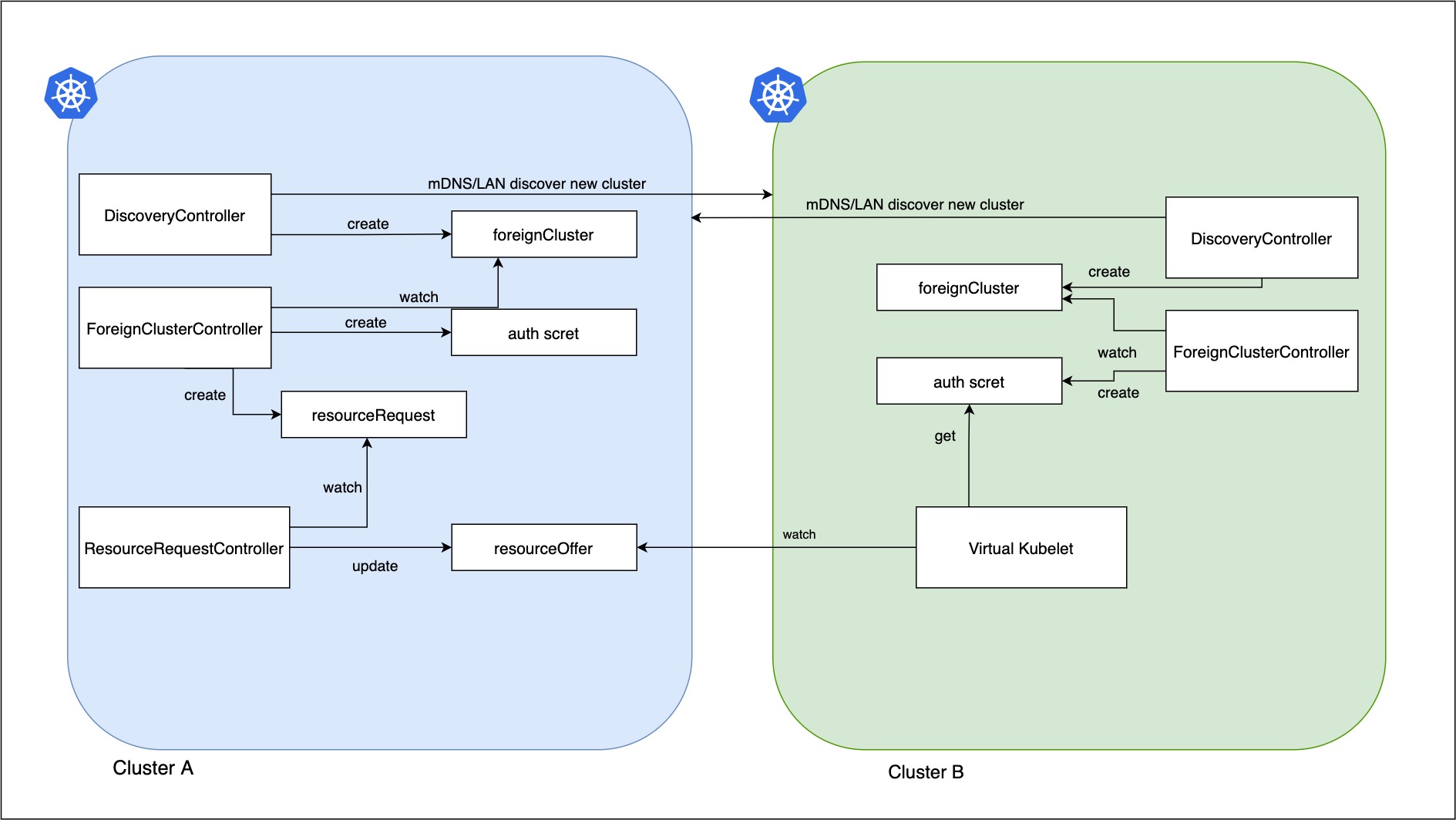
第一阶段:发现foreign cluster并上报可用资源
DiscoveryController是第一个集群注册的controller,DiscoveryController发现并创建 foreignCluster资源:通过WAN/LAN发现远端集群,将remote cluster的信息填入foreignCluster.spec,之后的Controller通过foreignCluster来获取remote cluster的信息。
ForeignClusterController监听foreignCluster CR,并维护remote cluster的identity信息。这些信息用来构建virtual kubelet,和crdReplicator使用。ForeignClusterController通过Authentication Service向远端的集群ForeignAuthURL验证remote cluster的身份信息,并将集群的证书存储在本地secret。
ForeignClusterController在确认foreign cluster期望outgoingPeering(即home cluster可以分享资源给foreign cluster使用),会创建 resourceRequest CR(不包含具体资源,只有集群元数据 authURL,用作后续资源请求的处理)。ResourceRequestController监听 resourceRequest CR,首先确保foreignCluster的foreignCluster/tenant资源存在;如果不存在则创建CR,确保ForeignAuthURL是resourceRequest.Spec.AuthURL。
ResourceRequestController负责监控本地资源,将需要更新共享资源配额的remote cluster id压入Broadcaster组件的队列里。将集群Broadcaster组件接着调用OfferUpdater.Push做资源同步。OfferUpdater负责组装resourceOffer里。resourceOffer的spec保存集群的可共享资源,供远端的virtual kubelet查询。
并且ResourceRequestController还会监听本地node/pod事件,维护集群资源缓存(将home cluster全局可用资源,和remote cluster占用资源分开)。当达到更新阈值(默认80%),也会主动调用OfferUpdate.Push更新可用资源。当创建pod时,集群资源减去pod资源;当pod有remoteClusterId标签(vk添加)时,会累加共享的remote集群的资源。做到区分本集群和remote pod,当集群资源-pod变化资源,会触发更新。
最终ResourceRequestController的OfferUpdater按序处理5、6步pushed的queue里集群id,获取home cluster集群资源并更新 home集群的 ResourceOffer 资源上限(offer.Spec.ResourceQuota.Hard) 。计算公式:(本集群可用资源量 + remote cluster的pod资源 )* ResourceSharingPercentage(依据配置共享给远端所有集群的资源)。
第二阶段:virtual kubelet监听home cluster的资源变化
从foreign cluster的角度,也会发现home cluster并创建相应的foreign cluster。virtual kubelet在foreign cluster注册时,初始化virtual-kubelet provider。在初始化的时候通过foreignClusterID拿到home cluster的kubeClient Config(上一阶段集群注册时生成的secret)。
LiqoNodeProvider监听resourceOffer资源(通过foreignClusterID获得自己的可用资源量)。从offer里的ResourceQuota中获的node的资源的Capacity和Allocatable值并调用 onNodeChangeCallback。 在virtual kubelet机制中,NodeProvider是被上层NodeController调用NotifyNodeStatus方法,来监控virtual node的变化。
实际的状态更新由NodeController定义的回调函数将节点信息压入channel,NodeController的控制循环实时异步地将资源变化向本集群的api server更新。
可以看到home cluster和foreign cluster没有本质上的区别,两者可以相互使用对方允许共享的机器资源。当然,集群A也可以配置成不贡献自己的资源出去,只使用别的集群分享出来的资源。
总结
本文介绍了KubeFed/Liqo两个开源项目多集群的资源管理和pod调度。
KubeFed的资源调度总体上比较静态,需要创建workload之前确保各集群有充足资源。它的动态调度能力有限,因为只能对Deployment/ReplicaSet开启。当KubeFed下发pod到集群出现pod pending的情况时,动态调度的能力能够将pod迁移到其他集群。
Liqo是能做到动态的资源发现和pod调度,但是它的方法是将一个集群抽象成一个工作节点。这种方式必然忽略了资源碎片的现象,使得虚拟节点的资源余量存在失真。比如集群内的2个节点共剩余40核可用资源,并不一定代表集群还能调度一个40核资源的pod。但是从Liqo的方式来看,这个集群是能够调度40核pod的。并且目前来看,如果集群内出现pod pending的情况,也没法自动迁移pod到其他集群。
不过Liqo的整个思想是比较新颖的,通过对等的P2P方式将多个集群聚合成一个大的可用资源池。对于现有集群也不会引入一套新的API。或许Liqo可以引入descheduler将pending pod迁移到其他机器来解决资源余量的误差问题。
参考
- A Brief History of Multicluster Kubernetes:https://www.tfir.io/a-brief-history-of-multicluster-kubernetes/
- Simplifying multi-clusters in Kubernetes:https://www.cncf.io/blog/2021/04/12/simplifying-multi-clusters-in-kubernetes/
- kubefed简介: https://jimmysong.io/kubernetes-handbook/practice/federation.html
- Unleashing the multi-cluster potential with Liqo: https://youtu.be/Ru-VrLcRXDg
- Virtual Kubelet: https://www.huweihuang.com/kubernetes-notes/virtual-kubelet/virtual-kubelet.html