k8s资源拓扑感知——资源分配
NUMA是什么
非统一内存访问架构(NUMA,Non-uniform memory access)是一种共享内存架构。与之相对的是统一内存访问架构(UMA,Uniform memory access),是指多个处理器通过统一总线访问存储器,每个处理器对内存的访问都是一致的。这种方式使得总线上的负载增加。在总线带宽有限的情况下,访问延迟增加。最常见的UMA架构就是 Symmetric Multiprocessor (SMP),对称多处理器结构,是指服务器中多个CPU无主次或从属关系,各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的。UMA除了基于总线共享外,还有其他架构实现方案。下图中(a)就是典型的SMP架构,(b)是由4个SMP相互连通的NUMA架构。
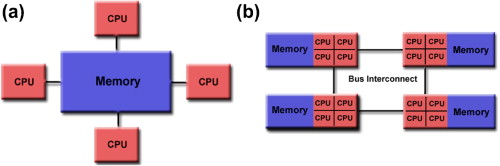
而NUMA的特点是每个处理器都有一个本地内存/群内共享内存,并且处理器还能访问其他处理的本地内存。在NUMA架构下,内存划分为不同的处理器。上图(b)的一个SMP内就是一个CPU群(group),一群CPU及其本地内存构成一个NUMA node。这里特别要强调一下,看外文文献的时候一定要看上下文区分NUMA node和k8s worker node。worker node是一台物理机/虚拟机,worker node可以采用NUMA架构。
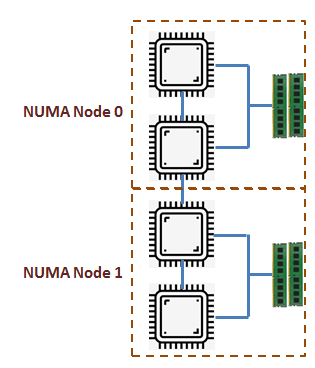
可以看到NUMA的共享内存分成:本地内存,群内共享内存,全局共享内存。内存访问时间取决于内存相对于CPU的距离。同一个node里的CPU访问本地/群内共享内存是要比访问其他node的共享内存要快的。本地和非本地内存的概念也被扩展到外部设备,比如网卡、GPU。为了获得高性能,应该考虑这个差异,分配 CPU 和设备需要考虑NUMA拓扑,以便它们可以访问相同的本地内存。
对于Linux来说,一个NUMA node包含多个CPU、本地内存和I/O总线。对于每一个node,Linux构造一个独立的内存管理子系统。Linux内核描述node的数据结构为pg_data_t。https://github.com/torvalds/linux/blob/512b7931ad0561ffe14265f9ff554a3c081b476b/include/linux/mmzone.h#L801
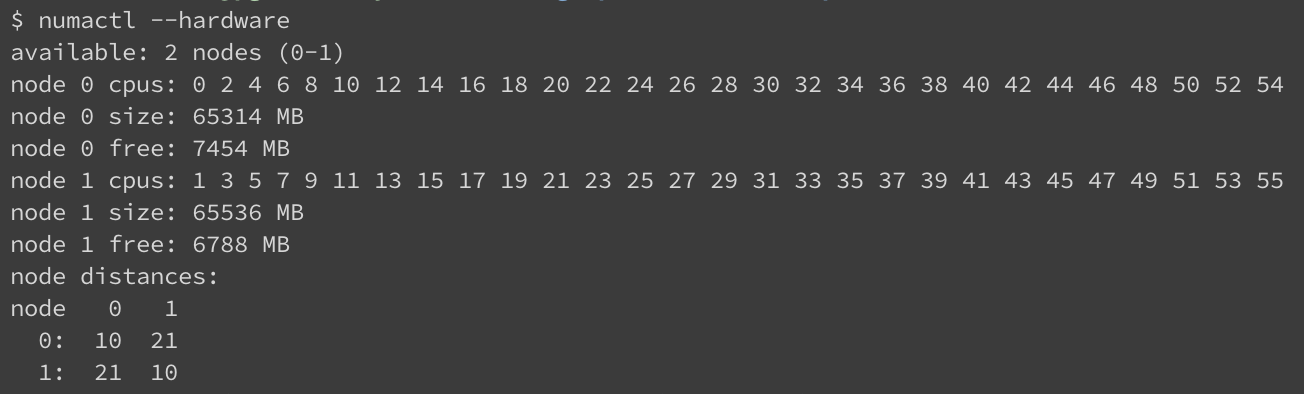
可以通过numactl命令查看机器上的NUMA node配置:这台机器有两个node,node distances是计算出来的node之间的访问时延,这个值是从ACPI SLIT(System Locality Distance Information Table)表里读出来的。node访问本地内存的时延是10,这是个基准值,仅作参考。而node 0和 node 1之间的时延为21,表示相比本地访问,跨节点访问的时延是2.1倍。而这个值是个相对值,具体的性能差异还是需要依据测试来验证。
k8s的NUMA亲和性
在k8s管理容器的组件里,与NUMA有关的组件是拓扑管理器(topologyManager) 。它属于是一个kubelet的一部分,旨在协调CPU 隔离、内存和设备局部性等优化的组件。该在v1.18是beta状态。在没有这个组件之前,kubelet的cpuManager、deviceManager都是相互独立地做出资源分配决策。这可能会导致最终的资源分配对应用性能起到副作用。例如,CPU和内存分配到不同的NUMA node上,导致额外的时延。
- containerManager:管理机器上的容器,创建并注册deviceManager,cpuManager,memoryManager,topologyManager。
- deviceManager:管理设备插件,通过gRPC和设备插件通信来获取设备状态。
- cpuManager:管理pod的cpu分配。
- memoryManager:管理pod的c内存分配。该功能在v1.21属于alpha阶段,v1.22提升到beta阶段。
- topologyManager:依据各硬件资源的topology hints,然后分配资源。该功能在v1.16属于alpha, v1.20提升到beta阶段。并且从v1.18开始默认开启。
- Internal Container Lifecycle:响应容器生命周期的调用(比如preStartContainer,postStopContainer),通过调用上述资源manager的AddContainer/RemoveContainer来分配和回收资源。
我们可以看到kubelet管理pod资源的演变路径是先有cpuManager管理cpu资源的分配,之后引入topologyManager和memoryManager。topologyManager会在admission阶段调用各资源manager的GetTopologyHints()/GetPodTopologyHints()获得资源的NUMA locality。而admission阶段也会调用资源manager的Allocate()方法来分配资源(存在kubelet维护的状态文件里,在之后的容器生命周期种,cri依据状态数据修改cpuset配置)。
Topology Manager
首先理清两个基本概念,NUMA node和k8s worker node。前文所说的NUMA node是逻辑概念,相邻的core(cpu0~3)组成一个NUMA node,同一个node内内存访问开销要比跨node访问要小。k8s worker node是一台服务机/虚拟机,提供容器的硬件资源和运行环境,kubelet作为机器上的第一层管理组件。一个k8s worker node依据处理器架构可以划分多个NUMA node。比如下图是8核cpu/两个NUMA node架构的worker node。
topologyManager是一个kubelet组件,提供给kubelet做出与拓扑结构相对应的资源分配决定。上述cpuManager/memoryManger等资源管理组件注册为HintProviders接口,提供底层资源的拓扑信息和分配硬件资源功能。topologyManager通过GetTopologyHints()/GetPodTopologyHints()从HintProviders获取资源的拓扑信息TopologyHint,结构包含作为表示可用的 NUMA 节点和首选分配指示的位掩码。
// HintProvider is an interface for components that want to collaborate to
// achieve globally optimal concrete resource alignment with respect to
// NUMA locality.
type HintProvider interface {
// GetTopologyHints returns a map of resource names to a list of possible
// concrete resource allocations in terms of NUMA locality hints. Each hint
// is optionally marked "preferred" and indicates the set of NUMA nodes
// involved in the hypothetical allocation. The topology manager calls
// this function for each hint provider, and merges the hints to produce
// a consensus "best" hint. The hint providers may subsequently query the
// topology manager to influence actual resource assignment.
GetTopologyHints(pod *v1.Pod, container *v1.Container) map[string][]TopologyHint
// GetPodTopologyHints returns a map of resource names to a list of possible
// concrete resource allocations per Pod in terms of NUMA locality hints.
GetPodTopologyHints(pod *v1.Pod) map[string][]TopologyHint
// Allocate triggers resource allocation to occur on the HintProvider after
// all hints have been gathered and the aggregated Hint is available via a
// call to Store.GetAffinity().
Allocate(pod *v1.Pod, container *v1.Container) error
}
TopologyHint包含:
- NUMANodeAffinity:纪录NUMA node满足资源请求的位掩码。
- Preferred:表示亲和性结果是否是首选的。如果hint存储了与预期不符的建议,则该建议的优选字段将被设置为 false。
map[string]topologymanager.TopologyHint{NUMANodeAffinity: newNUMAAffinity(0), Preferred: false}
拓扑作用域
拓扑作用域scope定义了资源对齐的颗粒度,目前支持下列两种资源对齐的作用域,通过kubelet的启动参数--topology-manager-scope来配置:
container:默认使用的作用域。对于单个容器独立计算资源分配结果,没有针对容器分组,计算NUMA亲和性。topologyManager会将单个容器任意地对齐到NUME node上。pod:允许把一个 Pod 里的所有容器作为一个分组,分配到一个共同的 NUMA 节点集。即:pod的所有容器可以分配到一个NUMA node,或者可以分配到一个共享的NUMA node集。当pod作用域与single-numa-node拓扑管理器策略一起使用,可以把单个Pod的所有容器都放到一个单个的 NUMA node, 使得该Pod内容器没有跨NUMA 之间的通信开销。
分配策略
TopologyManager首先计算出 NUMA 节点集,然后使用拓扑管理器策略来测试该集合, 从而决定拒绝或者接受 Pod。
分配策略policy定义了资源分配的具体策略,目前支持四种策略,通过kubelet的启动参数--topology-manager-policy来配置:
none:默认策略,不执行任何计算。best-effort:通过Hint Provider返回的结果,优先选择有首选(preferred)亲和性的node。如果亲和性不是首选,则topologyManager依然会接纳pod到这个node。restricted:同样通过Hint Provider返回的结果,优先选择有首选(preferred)亲和性的node。如果亲和性不是首选,则拓扑管理器拒绝此 Pod 。自此Pod处于Terminated状态,且 Pod 无法被节点接纳。并且k8s调度器不会重新调度pod之其他节点。single-numa-node:同样通过Hint Provider返回的结果,判断单 NUMA 节点亲和性是否可能。如果不满足,则拓扑管理器拒绝此 Pod ,并且pod无法被再次调度。
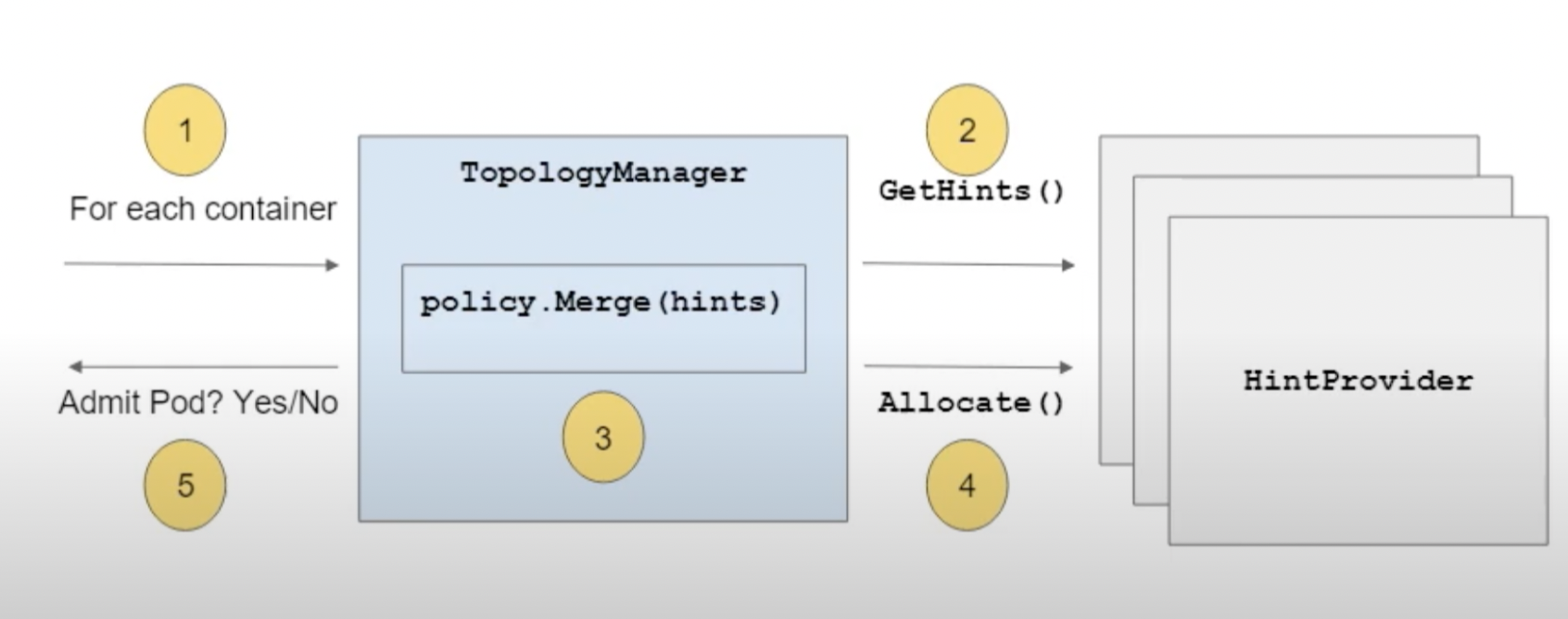
执行流程
- kubelet调用topologyManager处理新创建的pod,依据topologyManager结果判断pod是否能够在机器上启动。
- topologyManager依据拓扑作用域,调用hintProvider的GetTopologyHints()/GetPodTopologyHints()方法获得资源(例如cpu/memory/device)的NUMA node亲和性。
- topologyManager依据分配策略将hits合并成一个bestHint。依据策略会判断合并结果是否获准。如为否,则topologyManager选择拒绝pod的启动,kubelet将Pod状态phase设置为Failed并将TopologyAffinityError上报到reason。
- topologyManager调用hintProvider的Allocate()方法分配对齐后的资源。
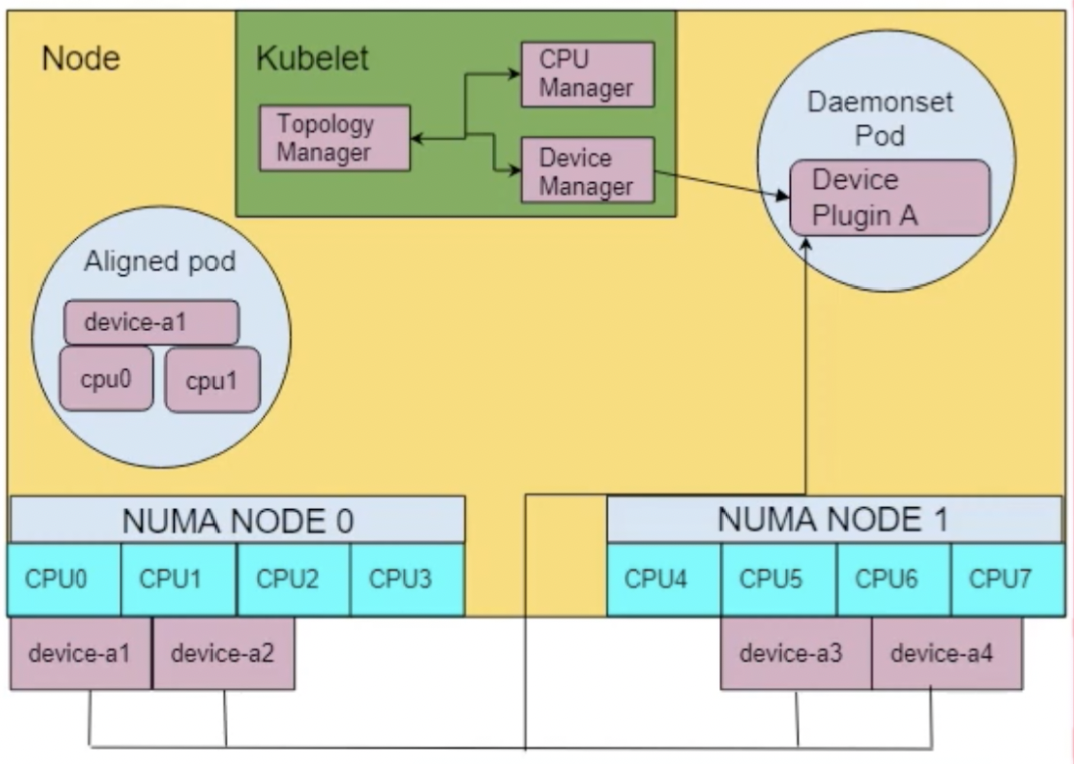
如图所示,硬件被分布到2个NUMA node,每个node都有4个cpu、本地内存、和外接设备资源。其中NUMA node 0有2个NIC,NUMA node 1有2个GPU卡。
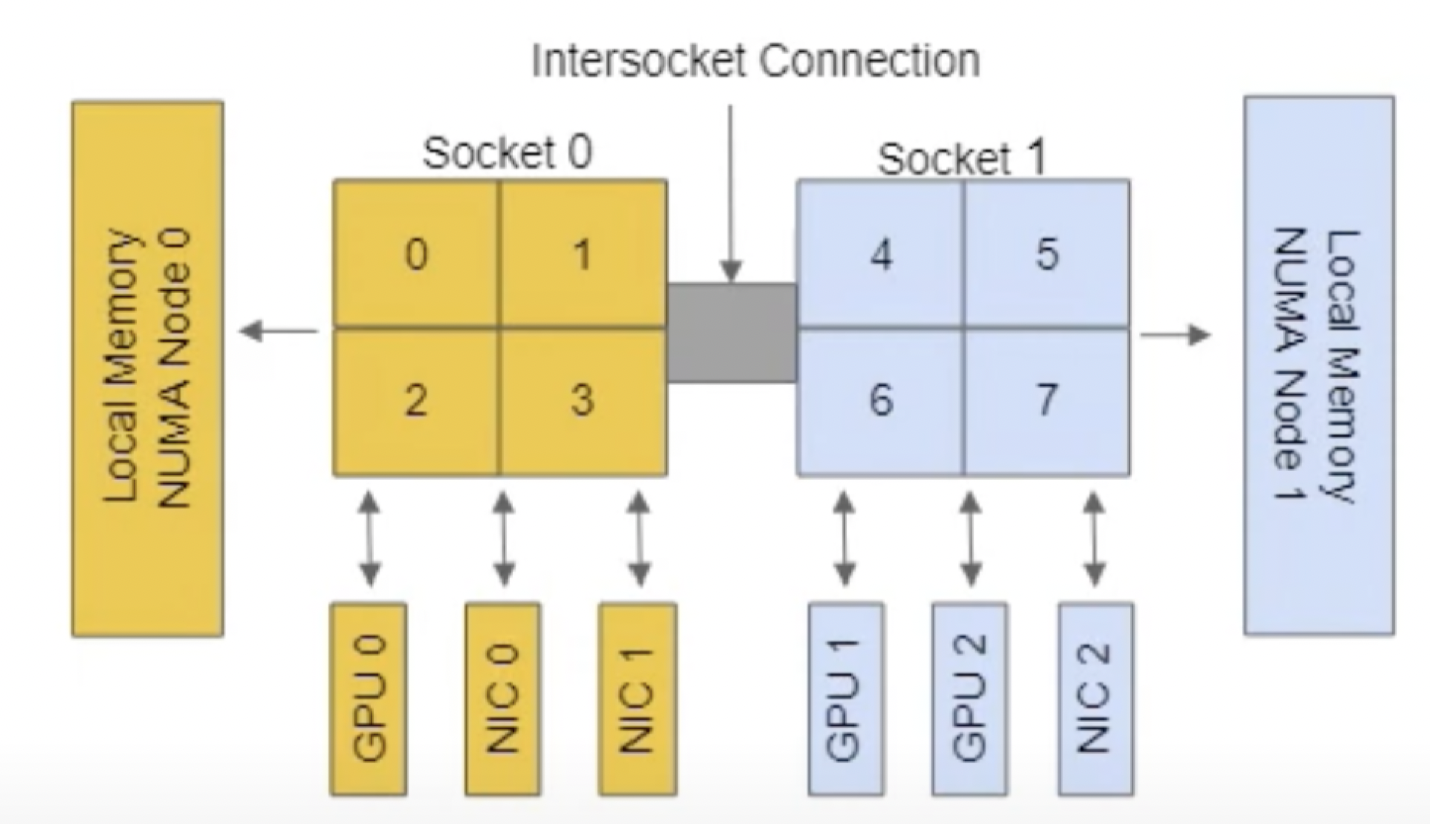
如果Pod的请求资源如下:
kind: Pod
spec:
containers:
request:
memory: 1Gi
cpu: 1
nic-vendor.com/nic: 1
gpu-vendor.com/gpu: 1
TopologyManager首先会依据pod声明的资源请求,调用各资源manager的方法获取TopologyHit。TopologyHit的bitmask的长度是2,分别表示node 0、node 1是否被分配。
例如CPU资源的结果,hint结果{01 true}、{10 true}表示单独分配NUMA node 0、1,true表示这种分配为首选的。{11 false}表示同时分配NUMA node0、1,因为资源分配跨NUMA node,所以这种分配不是首选的。对于NIC和GPU资源也是[{01 true} {10 true} {11 false}]。依次类推,可以看到图上3种NUMA感知的资源分配情况:
cpu: [{01 true} {10 true} {11 false}]
nic: [{01 true} {10 true} {11 false}]
gpu: [{01 true} {10 true} {11 false}]
第二阶段是TopologyManager合并所有的TopologyHit。首先对NUMANodeAffinity做跨资源做位与运算。对于Preferred字段,,只有所有的条目中为true的组合的合并结果才为true。上述case的最终hit为{01 true}。对于best-effort、 restricted、 single-numa-node策略,{01 true}都是获准的。最终的硬件资源都在NUMA node 0上。
如果NUMA node1上的GPU 1不可用,并且Pod申请2张gpu卡。关于cpu、nic的hints结果不变,而gpu的hits只能得到[{11 false}],表示GPU分配跨NUMA node,并且不是首选结果。因为首选是分配GPU 1、GPU2,只是GPU 1不可。对于best-effort、 restricted策略来说,最终合并的结果为{01 false},即分配到NUMA node 1上但是不是首选的结果。所以best-effort策略会批准这个分配,而restricted策略不会批准,因为这个分配结果不是首选的。对于single-numa-node策略的合并结果为{11 false},由于跨NUMA node,分配也不会批准。
如果NUMA node1上的GPU 1保持可用,但是Pod申请3张gpu卡。这时gpu的hits变成[{11 true}],表示GPU分配跨NUMA node,并且是首选结果(只能有这一种跨NUMA node分配GPU的方式)。
通过这3个例子可以看出,topology策略restricted和single-numa-node的区别。对于restricted策略来说,最终获准的条件是各资源分配的Preferred字段,如果跨NUMA node分配是资源分配的唯一解,那边这种策略是会放行的。而single-numa-node策略更加严格,只要跨NUMA node分配就会被拒绝。
当前在kubelet中,topologyManager主要完成下列事项:
- 调度用多个hint providers,获得各个子管理域的可分配情况
- 编排整体的拓扑分配决策
- 提供“scopes”和policies参数来影响整体策略
CPU Manager
介绍完拓扑感知的基本内容,之后详细分析cpuManager和memoryManager的原理。cpuManager提供HintProvider的方法:GetTopologyHints()/GetPodTopologyHints()/Allocate()之外,还提供AddContainer()/RemoveContainer()的接口,分别在preStartContainer/postStopContainer阶段被调用。这两个方法都是幂等的。在方法调用中依据具体的策略,将容器分配到机器的cpu上。
Cpu manager策略有: none,static,dynamic三种。
- none:默认策略,不做任何事情。不会有cpuset.cpus和cpuset.mems的控制。
- static:依据pod的QoS分配。guaranteed QoS pod是所有的容器(包括containers/initContainers)的cpu和内存资源limits和requests必须显性配置并且资源量相等。对于Guaranteed的pod,并且资源是整数量,会配置cpu的独占,即绑核。这些被分配的cpu不会共享给其他容器使用。
- dynamic:在容器的生命周期内动态分配cpu,cpuset可能会被更新。所以容器内的进程需要感知cpu分配的变化。这个策略目前社区也未实现。
cpu拓扑结构在kubelet里的结构如下:记录NUMA,socket以及 core IDs信息。socket是一个物理上的概念,指的是主板上的cpu插槽。node是一个逻辑上的概念,是相邻core的一个分组。core一般是一个物理cpu,一个独立的硬件执行单元。thread是逻辑的执行单元,一般对应 cpu 的核数。
&topology.CPUTopology{
NumCPUs: 8, // CPU - logical CPU, cadvisor - thread
NumSockets: 1, // Socket - socket, cadvisor - Node
NumCores: 4, // Core - physical CPU, cadvisor - Core
CPUDetails: map[int]topology.CPUInfo{
0: {CoreID: 0, SocketID: 0, NUMANodeID: 0},
1: {CoreID: 1, SocketID: 0, NUMANodeID: 0},
2: {CoreID: 2, SocketID: 0, NUMANodeID: 0},
3: {CoreID: 3, SocketID: 0, NUMANodeID: 0},
4: {CoreID: 0, SocketID: 0, NUMANodeID: 0},
5: {CoreID: 1, SocketID: 0, NUMANodeID: 0},
6: {CoreID: 2, SocketID: 0, NUMANodeID: 0},
7: {CoreID: 3, SocketID: 0, NUMANodeID: 0},
},
}
当没开启NUMA时,默认为一个NUMA node包含全部的cpu。这时的cpu分配算法时topology-aware best-fit:依据sockets、物理核、逻辑核的优先级填充。
- 1)当需要的cpu数不小于一个socket上的cpu数时,优选分配一个socket上的全部CPU,即独占一个socket。
- 2)当剩余所需cpu数未达到一个socket的大小时,并且所需cpu数不小于一个物理核的逻辑核数时,优选分配一个core上的cpus,即独占一个物理核。
- 3)最后,则优选填充之前分配导致的部分分配的socket/core上空闲的cpus。
比如上面这个CPU拓扑的情况下:当容器需要2核时,依据best-fit分配cpu 0出去; 需要分配2核时,分配 cpu 0, 4,因为在一个core上。cpuManager会依据策略的结果,在文件中更新cpuset的状态。之后kubelet调用CRI的接口,更新容器的资源。
* 注:v1.18之后,policy.AddContainer()重命名为policy.Allocate(),作为HintProvider给topologyManager在admission阶段调用。
Memory Manager
内存是依托于memoryManager(v1.22 beta)这个新组件来分配的。和cpu mananger类似,分配策略有两种: none,static。
- none:默认策略,不做任何事情。
- static:对于Guaranteed的pod,在容器启动前分配内存。
memoryManager内部维护一个NUMANodeMap对象,该对象记录Guaranteed pod里的容器内存使用量(包括hugepages)。memoryManager通过NUMANodeMap计算出preferred NUMA affinity,并且返回hint给topologyManager。hint指明哪个NUMA node或者哪组NUMA node最合适锁定内存分配给容器。依据topologyManager的范围(container或者pod),有两个不同的hint产生路径:
GetTopologyHintsforcontainerscopeGetPodTopologyHintsforpodscope
在admission阶段(通过kubelet调用Admin()),memoryManager使用Allocate()更新NUMANodeMap,记录一个容器所请求的内存和hugepages,起到预分配的作用。 之后kubelet调用AddContainer,记录容器和pod的映射关系。最后,通过CRI接口,更新cgroups( cpuset.mems)当pod的admission阶段没有容器被拒绝,pod最终会被部署到宿主机上。
Linux内核本身不支持多NUMA的内存分配(内存锁定,memory pinning)。memoryManager的主要思路是将一组NUMA nodes作为一个独立单元来管理,节点是不相交的,NUMA node不能跨组。Guaranteed的pod的内存分配可以跨多个NUMA nodes。当容器的内存请求超过单NUMA node的容量时,通过NUMA 组的概念允许跨NUMA node的内存分配。分配原则是,最小数量的NUMA nodes来分配内存资源。比如下图NUMA nodes[1, 2]就属于同一组,容器A、C的内存请求都超过了单NUMA node的内存容量,所以分配到一组[1, 2]里。
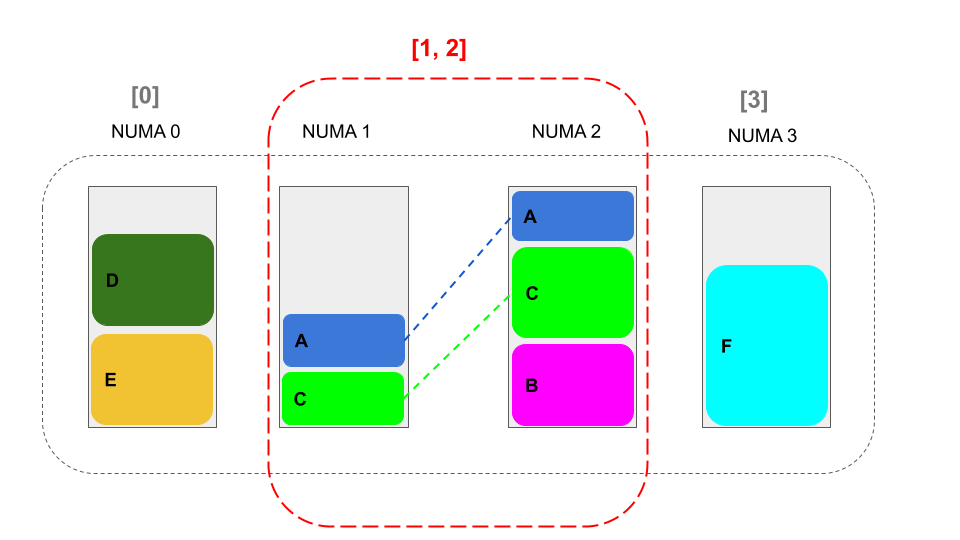
当宿主机NUMA未开启时,默认以一个NUMA block。memoryManager会调用topologyManager获取NUMA亲和信息。当kubelet没有开启topologyManager的话,则通过topologyManager提供空hint。此时,memoryManager会自行计算一个NUMA affinty。并且成功分配时会在本地保存machineState保持预留信息和容器内存资源assignments的分配信息。
- machineState:保存每个NUMA node的内存(常规内存和hugepages)信息,包含内存的资源信息和已经分配数,和同组的numa node。numa node组是不相交的。每次Allocate时,memory manager都会获取当前的machineState,并且将容器请求的资源更新为已经部署的容器的资源预留。
state.NUMANodeMap{
0: &state.NUMANodeState{
MemoryMap: map[v1.ResourceName]*state.MemoryTable{
v1.ResourceMemory: {
Allocatable: 1536 * mb, // Allocatable = TotalMemSize - SystemReserved
Free: 1536 * mb, // Free = Allocatable - Reserved
Reserved: 0, // Reserved = Allocatable - Free
SystemReserved: 512 * mb,
TotalMemSize: 2 * gb,
},
hugepages1Gi: {
Allocatable: gb,
Free: gb,
Reserved: 0,
SystemReserved: 0,
TotalMemSize: gb,
},
},
Cells: []int{0}, // NUMA node id in same group
},
}
- assignments:保存容器的内存分配结果。每次Allocate时,保持容器的内存块分配结果,包含内存资源大小和NUMA亲和性。
state.ContainerMemoryAssignments{
"pod1": map[string][]state.Block{
"container1": {
{
NUMAAffinity: []int{0},
Type: v1.ResourceMemory,
Size: gb,
},
{
NUMAAffinity: []int{0},
Type: hugepages1Gi,
Size: gb,
},
},
},
}
计算默认 topologyHint
当topologyManager未开启或者没有提供NUMA亲和性时,memoryManager会自行计算默认的topologyHint。一个hint表示一个的满足内存资源需求的NUMA nodes集合。例如0100表示,总共有4个 NUMA nodes,编号:0-3。其中3号node有足够的内存资源。二0110表示需要跨1、2号NUMA nodes才能满足内存需要。
算法的输入是machineState、新建的pod和容器所需内存资源(包括常规内存和hugepages)。输出是拓扑感知提示(TopologyHint)。
首先依据machineState输入的NUMA nodes,遍历NUMA nodes,每次遍历都累积位掩码:
- 统计每个Node上的内存资源总量和空闲量,并确保资源总量能够满足容器请求。
- 统计ReusableMemory并算作该NUMA节点的可用资源:同一个pod的initContainers可以作为可回收。确保NUMA node空闲量+ReusableMemory能够满足容器请求
- 将资源分布的位掩码存成一个topologyHint,作为分布策略。统计每次遍历时,更新满足资源请求的最小NUMA亲和节点大小
minAffinitySize。 - 最终遍历所有的topologyHint,设置各hit是否为首选。如果掩码长度等于
minAffinitySize,表明hit的分配为NUMA亲和性的首选。
总结
本文简单介绍了kubelet中负责资源拓扑感知和分配的组件。topologyManager负责判断pod的资源拓扑是否满足需求,在其之下的cpuManager/memoryManager/deviceManager提供相应资源的NUMA亲和性。topologyManager依据策略综合各资源的NUMA亲和性计算出pod的容器是否允许运行。这些组件相互合作,保障单机层面上的NUMA拓扑的性能保障。但是对于集群层面的资源发现和调度,社区还处在于讨论 阶段,主要考虑的点在于是否在调度器重复处理资源亲和性的逻辑。当然,社区中也有初步实现调度感知的软件。
局限性:
- 调度器不是拓扑感知的。有可能一个 Pod 被调度之后,会因为拓扑策略在节点上启动失败。
- memoryManager本身没有涉及内核关于多NUMA node的内存分配,所以只是在应用层限制了内存的分配。
参考
- 服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA): https://www.cnblogs.com/linhaostudy/archive/2018/11/18/9980383.html
- What is NUMA: https://www.techplayon.com/what-is-numa-non-uniform-memory-access/
- Linux kernel view of NUMA: https://www.kernel.org/doc/html/latest/vm/numa.html
- what is ACPI slit:https://www.codeblueprint.co.uk/2019/07/12/what-are-slit-tables.html
- [kep] cpu manager: https://github.com/kubernetes/enhancements/blob/f343d8b94f8b83e8496ae42313f1290c1767bba6/keps/sig-node/375-cpu-manager/README.md
- [kep] topology manager: https://github.com/kubernetes/enhancements/blob/7eef794bb549a50c6b08c457556ff0eac98a4c6b/keps/sig-node/1029-ephemeral-storage-quotas/README.md
- [kep] memory manager: https://github.com/kubernetes/enhancements/blob/ea90443458c3832d9770868f95aaf0d2fbc42dc2/keps/sig-node/1769-memory-manager/README.md
- Kubernetes Topology Manager: https://kubernetes.io/blog/2020/04/01/kubernetes-1-18-feature-topoloy-manager-beta/
- Control Topology Management Policies on a node: https://kubernetes.io/docs/tasks/administer-cluster/topology-manager/
- [video] Optimized Resource Allocation in Kubernetes? Topology Manager is Here: https://www.youtube.com/watch?v=KU_EtejzXp0&ab_channel=CNCF%5BCloudNativeComputingFoundation%5D